用了这么久 Claude Code,可能就差在这里
用 Claude Code 写了三个月代码后,一个规律越来越明显:大多数效率瓶颈不在模型能力上,在配置和工作习惯上。
同样一个需求,有人 10 分钟跑通,有人反复纠正半小时。差别往往就在几件事上——CLAUDE.md 有没有写好、权限和 Hooks 有没有配、快捷键熟不熟、工作流节奏对不对、用量怎么管。
下面是提升效率和安全性最值得投入的几个方向。
CLAUDE.md —— 项目的”说明、记忆和规范引擎”
Claude Code 每次启动自动读取 CLAUDE.md,不需要手动喂。读取优先级:
子目录 CLAUDE.md > 项目根目录 CLAUDE.md > 全局 ~/.claude/CLAUDE.md
项目级覆盖全局,子目录覆盖项目级。
如果你还没有系统地用过 CLAUDE.md,建议先看看 CLAUDE.md 配置完整指南,里面有从基础到高级的写法详解。
放什么
放代码里推断不出来的东西:架构决策、编码规范、测试流程、Git 分支策略、禁止修改的文件路径。
别把代码库已有的信息再抄一遍——浪费 Token,还容易和代码实际情况冲突。
怎么编写
- 控制在 100-200 行。太短不够用,太长指令上下文爆炸。
- 子弹句式 + 一级标题,模型解析效率最高。命令放代码块,指标放数字,不写长段叙述。
- 持续迭代:任务结束后说
update CLAUDE.md so this never happens again,让 Claude 把踩过的坑自己写进去。 - 快速追加:用
#开头的消息直接追加到 CLAUDE.md。用@docs/architecture.md引用外部文件,不用什么都塞进一个文件。
CLAUDE.md 不是写一次就完的文档,是你和 Claude 共同维护的工作协议。把它当成配置即契约来对待,效果会好很多。
子目录 CLAUDE.md:Monorepo 的隐藏加分项
子目录 CLAUDE.md 的覆盖机制在 monorepo 里特别有用。比如一个典型的前端 monorepo:
repo/
├─ CLAUDE.md ← 全局:Git 规范、CI 流程、禁区
├─ packages/
│ ├─ pc/CLAUDE.md ← PC 端:Vue 2 + Element UI
│ └─ mobile/CLAUDE.md ← 移动端:Vue 3 + VantClaude 在 packages/mobile/ 下工作时,会同时读取根目录和子目录的 CLAUDE.md,子目录优先。全局放公共约束(Git 流程、审查标准),子目录放各端差异(框架版本、组件库、构建命令),互不干扰。
后端微服务项目同理——每个服务目录放自己的 CLAUDE.md,覆盖全局的语言版本、ORM 约定、部署方式。
除了项目级 CLAUDE.md,Claude Code 还支持用户级规则(User Rules)——写在全局设置里,对所有项目生效。适合跨项目通用的偏好,比如「总是用中文回复」「不要主动重构没提到的代码」「每次回答先给结论」。
权限配置与 Hooks —— 从”口头约定”到”硬规则”
Claude Code 的权限和自动化行为通过 .claude/settings.json 配置,也有优先级:
全局 ~/.claude/settings.json → 项目 .claude/settings.json(项目级覆盖全局)
权限规则
{
"permissions": {
"allow": ["Read", "Glob", "Grep", "Bash(npm test:*)"],
"deny": ["Bash(rm:*)", "Bash(git push --force:*)"]
}
}allow 里的工具自动放行,不用每次点确认。deny 里的命令直接禁止执行。Bash(npm test:*) 表示所有以 npm test 开头的命令都自动允许——省掉频繁审批的摩擦,同时把高危操作锁死。
Hooks
Hooks 是另一个能力维度——在工具执行前后自动跑脚本。配置也写在 settings.json 里:
{
"hooks": {
"PreToolUse": [
{
"matcher": "Bash",
"hook": "node ./scripts/check-safety.js"
}
],
"PostToolUse": [
{
"matcher": "Edit",
"hook": "npx prettier --write \"$FILE_PATH\""
}
]
}
}常用场景:
PreToolUse:工具执行前拦截。比如 Bash 命令执行前做安全检查,或阻止对特定目录的写入。PostToolUse:工具执行后自动跑。比如每次编辑文件后自动格式化,每次 Git 操作后刷新状态。Notification:长任务完成后发通知,不用盯着终端等。
权限管的是”Claude 能不能做这件事”,Hooks 管的是”做之前/之后自动插入什么动作”。两者配合,就是把 CLAUDE.md 里那些口头嘱咐变成系统级的规则和流程。
快捷键与常用命令
Claude Code 的交互节奏快,鼠标跟不上。把快捷键和高频命令放一起说。
快捷键与命令一览
| 快捷键 / 命令 | 功能 |
|---|---|
Esc | 立即停止当前工具执行 |
Esc × 2 | 回到上一个检查点,代码 + 上下文一起回滚 |
Shift + Tab × 2 | 切换 Plan Mode(只规划不执行) |
! 命令 | 直接执行 Shell,输出进入上下文,Claude 可继续判断 |
@文件名 | 精确注入上下文,如 @src/components/Button.tsx |
/clear | 清空上下文 |
/btw | 不打断任务、插问一句,Claude 回答后继续手头工作 |
/simplify | 审查并精简刚写的代码,找冗余直接改掉 |
/init | 让 Claude 自动生成 CLAUDE.md 骨架 |
/plan | 进入规划模式,等价于 Shift+Tab × 2 |
/compact | 手动触发上下文压缩 |
/rewind | 回滚到指定步骤(见下方说明) |
/context | 查看当前上下文里装了什么 |
/permissions | 查看和管理当前权限规则 |
几个用法值得单独说一下:
Esc × 2 是最重要的安全网。Claude 改错了代码,双击 Esc 回到上一个检查点,代码和对话上下文一起回滚,不用手动 git stash。
! 命令 在对话里直接跑 Shell。! npm run build 的输出直接进入上下文,Claude 能看到结果继续判断,不用切窗口。
/btw 适合对话中途冒出来的小疑问,比如 /btw 你刚才说的 tree-shaking 具体指什么?——Claude 回答完继续执行,不把它当新指令处理。
/clear 建议每个新任务都用一次。旧对话堆积会让模型”记混”,清空是低成本高收益的习惯。
/compact 与上下文压缩
Claude Code 的上下文窗口是有限的。对话轮数多了,早期的对话会被自动压缩——系统会把旧的对话轮次摘要化,只保留关键信息(系统提示、CLAUDE.md、最近几轮的工具结果),更早的交互被浓缩成摘要。
/compact 是手动触发的入口——当你觉得”模型好像忘了前面的事”或者”响应变慢了”,跑一次 /compact 可以主动释放上下文空间。更多关于上下文管理的策略,可以参考上下文管理指南。
但压缩有代价:被压缩的内容只剩摘要,细节会丢。所以重要的约束和规则应该放在 CLAUDE.md 里(每次都会重新注入),而不是靠对话历史”记住”。
为什么不建议所有工作都在一个长会话完成?
有人会说 KV cache 能复用上下文,长会话更经济。实际用起来,这个账不是这么算的。
对话越长,模型的召回质量越低。早期的约束和规范会被淹没在后续轮次里,不是”忘了”,是注意力被稀释了。这正是 AI 编程助手在长期维护项目中表现不稳定的核心原因之一。
长会话里也容易积累冲突的指令。前面说「用 TypeScript」,后面说「这个文件用 JavaScript」,模型会在两者之间犹豫,判断质量下降。
出错返工的代价也更高。在第 50 轮发现方向跑偏,纠正成本远超在第 5 轮换一个新会话重来。来回往复,既没省 token,也浪费了时间。
一个任务一个会话,每次用 CLAUDE.md 重注入约束,是更稳的节奏。
/rewind:精确回滚
/rewind 可以回到对话中的任意一步。比如 Claude 前 3 步都对了,第 4 步跑偏了——用 /rewind 回到第 3 步的状态,代码和上下文一起恢复,不用从头来。
核心工作流:Plan → Implement → Verify → Commit
Claude Code 的工作原理是「模型决策 → 工具执行 → 结果回流 → 模型再决策」的循环。每一步工具调用的结果都会喂回模型,它沿着真实证据往下走,而不是靠一次性推理猜完所有事。
理解这个机制,工作流的每个阶段就有了不同的意义。如果你想系统地了解这个流程,可以看看探索-计划-编码工作流的完整方法论。
1. Plan(探索与规划)
先让 Claude 主动读项目,而不是靠你口述结构。比如:
告诉我当前的项目鉴权流程是怎么走的它会调用 Read、Glob、Grep 工具,把文件内容拿回来喂进上下文,再决定下一步看什么。这个过程是真实的工具调用,不是猜。
用 @src/auth/ 注入目录上下文也可以,但让它主动 Explore 的好处是它会顺着代码跑——发现一个引用就去看引用,发现一个依赖就去看依赖,理解通常更完整。
复杂任务可以让它先出一份探索报告:
先不要改任何东西,把你对这个模块的理解整理成一份报告给我看确认它理解对了,再进入规划。用 Shift+Tab × 2 进入 Plan Mode,或者直接说:
先别写代码,给我一个实现方案,列出要改哪些文件、每个文件改什么Plan Mode 下 Claude 只输出分析,不调用任何工具,不改任何文件。适合在动手前对齐方向——多文件改动、涉及接口变更、或者你对方案有疑问时,这步不能省。确认方案没问题再退出 Plan Mode 开始执行。
如果你觉得每次手动切换 Plan Mode 太麻烦,可以试试 Auto Plan Mode——让 Claude 根据任务复杂度自动判断是否需要先规划。
2. Implement(实现)
执行阶段,Claude 会自己调用 Edit、Bash 等工具。每次工具调用的结果都会回流进它的下一轮判断:改完一个文件,它会自己决定下一步是继续改还是先跑测试看看。
这个阶段你能看到它不断地「改→看结果→再改」,而不是一口气输出所有代码。工具结果是它的证据,它沿着证据走。
如果中途有小疑问,用 /btw 随手问,不打断执行流。
3. Verify(验证)
验证是人工介入最密集的阶段。重点看三件事:测试结果有没有报错、文件改动是否符合预期、实测效果和需求有没有偏差。这一步也适合跑 /simplify——让 Claude 审查刚写的代码有没有冗余,发现了直接改掉。
4. Commit(提交)
验证通过后:
帮我提交这次改动,commit message 用中文Claude 会自动 git add 相关文件、生成 commit message、执行 git commit。如果在 CLAUDE.md 或 settings 的 User Rules 里配置了 Git 规范(分支命名、commit message 格式、禁止 force push 等),提交时会自动遵守,不需要每次口头重申。
简单任务可能 30 秒走完全程,复杂任务每一步都值得停一眼。节奏比速度重要。这套工作流的更多实战细节,团队实战技巧里有更详细的分享。
进阶:用 Codex 做交叉审查
如果你同时装了 OpenAI 的 Codex 插件(codex-plugin-cc),可以在 Verify 阶段用 /codex:review 让 Codex 来审查 Claude Code 写的代码。
让另一个厉害的 AI 来审查 AI 写的代码。两个模型的盲区不完全重叠,交叉审查能捞到单模型漏掉的问题。这个流程不是必须的,但在关键模块或上线前值得跑一次。

周边工具:ccusage 和 cc-switch
Claude Code 本身不告诉你用了多少钱。这两个社区工具补上了这个缺口。如果你还不清楚 Claude Code 的计费逻辑,可以先看看计费模式详解。
ccusage:看用量
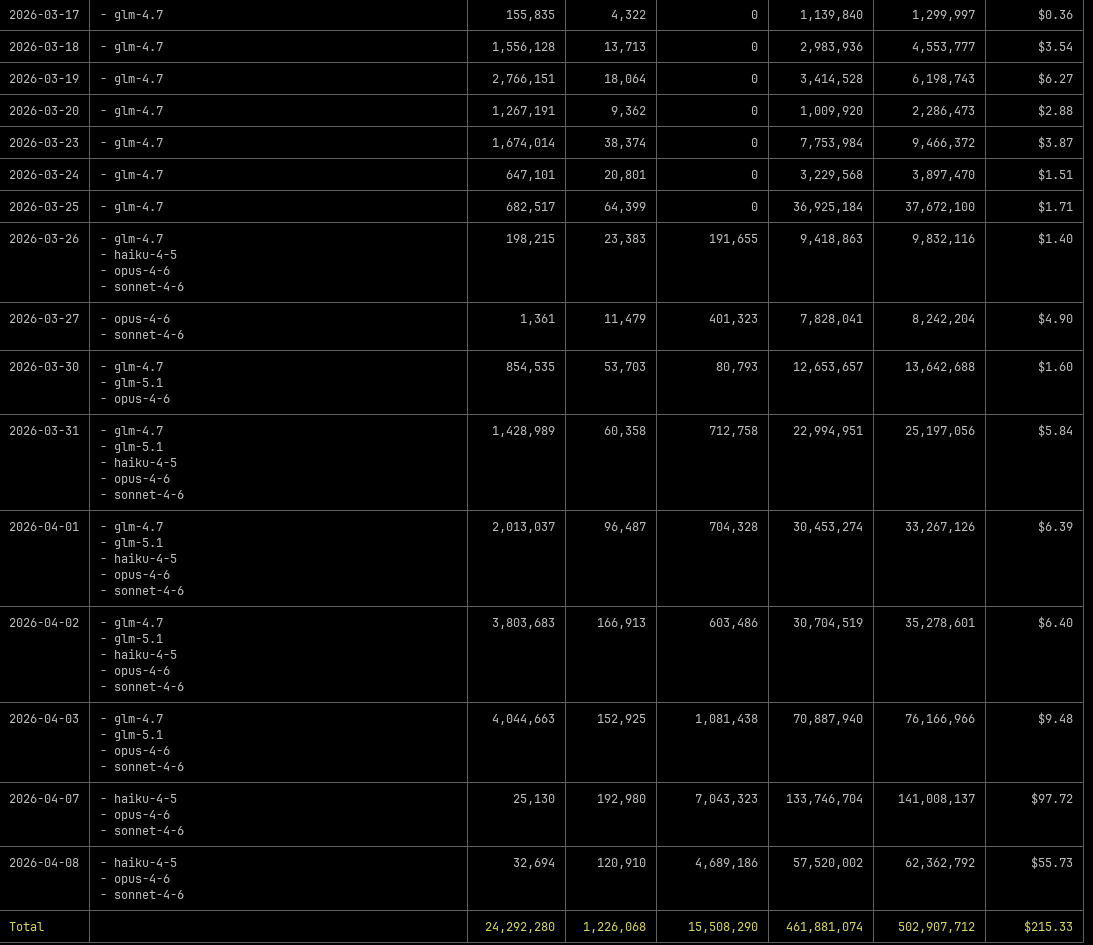
ccusage 读取本地日志,统计 Token 消耗和费用:
npx ccusage@latest一条命令看到今天、本周、本月的消耗。Max 订阅用户用它判断有没有接近限额,API 用户直接看钱花在哪了。
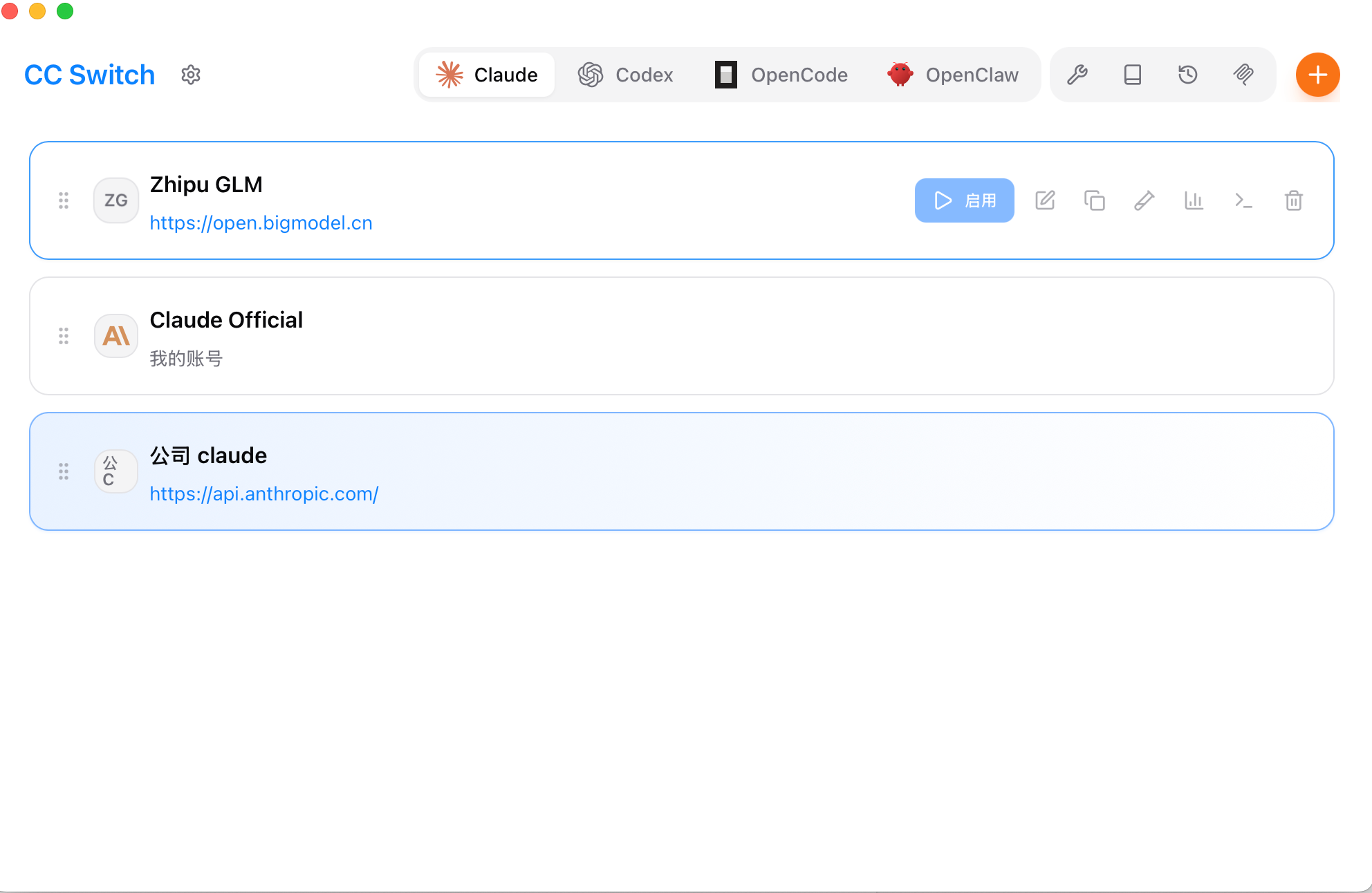
cc-switch:多配置管理
多个项目、多个账号之间切换(比如个人项目和公司项目用不同的 API Key),手动改配置容易出错。cc-switch 提供了界面化方式来管理和切换 Claude Code 配置,省去每次手编 settings.json 的麻烦。
结尾
还有一点是目前 Claude 对国内封锁严重,其实真可以用国产模型作为备选和平替,就我的体感来说,目前的 glm-5.1 和 sonnet 4.6 相当。
相关阅读:
- CLAUDE.md 配置完整指南 - 从基础到高级的 CLAUDE.md 写法详解
- CLAUDE.md 至上原则:配置即契约 - 理解为什么 CLAUDE.md 是 Claude Code 的核心
- 计划模式:先规划再执行 - Plan Mode 的完整用法
- 上下文管理 - 控制上下文容量与协作质量
- 探索-计划-编码工作流 - 系统化 AI 开发方法论
- Claude Code 计费模式 - 用量与费用管理